lab1 utilities
sleep.c
一些资源
- 梳理xv6系统调用的流程
- xv6的所有系统调用的签名都定义在
user/user.h中 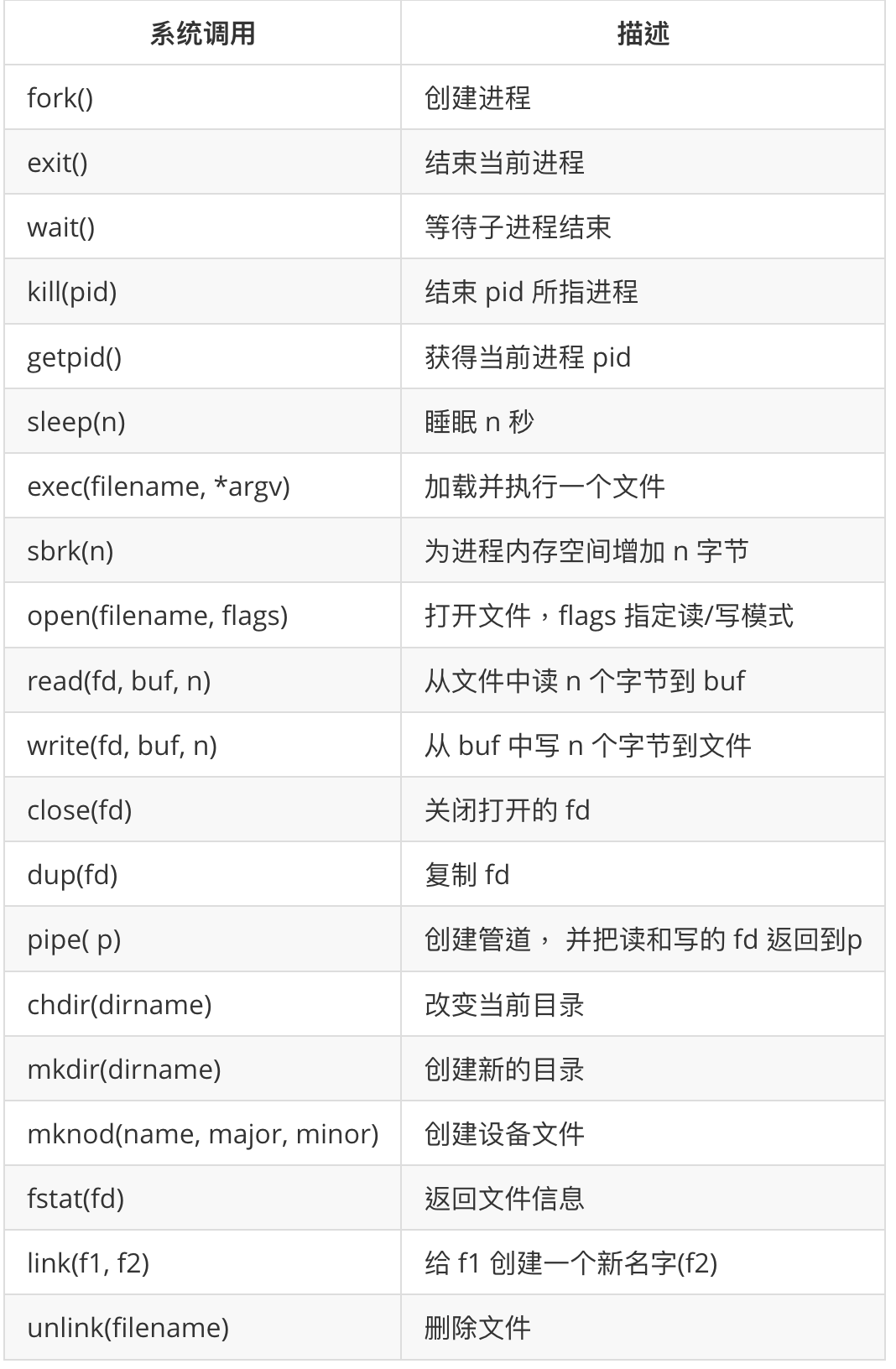
1)
Look at some of the other programs in user/ (e.g., user/echo.c, user/grep.c, and user/rm.c) to see how you can obtain the command-line arguments passed to a program.
1
int main(int argc, char *argv[])
main函数接受两个命令行参数:
argc:命令行参数的数量(包括程序名称本身,如echo);argv:一个字符串数组,包含所有的命令行参数。argv[0]是程序名称,argv[1]是第一个参数,以此类推;2)
If the user forgets to pass an argument, sleep should print an error message.
1
2
3
4
if(argc <= 1){//如果只输入了程序名称argv[0]或者连程序名称都没有
fprintf(2, "usage: sleep seconds\n");//第一个参数2表示输出到
exit(1);
}
其中fprintf函数用于输出错误信息,其第一个参数表示:
- 0: 标准输入 (stdin)
- 1: 标准输出 (stdout)
- 2: 标准错误 (stderr)
3)
**The command-line argument is passed as a string; you can convert it to an integer using atoi.
1
2
3
4
5
6
7
8
9
10
11
//这里是我不小心复制错了,不过了解一下这个stat函数也挺好的
int stat(const char *n, struct stat *st)
{
int fd = open(n, O_RDONLY); //打开文件,并返回文件描述符fd
if(fd < 0) return -1;
int r = fstat(fd, st);
close(fd);//关闭文件的系统调用
return r;
}
open是一个系统调用,用于打开或创建一个文件,并返回一个文件描述符fd(file descriptor)。文件描述符是一个非负整数,后续可用于对该文件进行读写等操作。
参数1n:要打开的文件名或路径
参数2O_RDONLY:打开模式标志(flag),这里表示以”只读”模式打开fstat也是一个系统调用,用于获取已打开文件的状态信息。它接收一个文件描述符作为参数,然后将该文件的详细信息填充到一个结构体(比如上文的st)中。
1
2
3
4
5
6
7
8
//这个是atoi函数
int atoi(const char *s)
{
int n = 0;
while('0' <= *s && *s <= '9')
n = n*10 + *s++ - '0';
return n;
}
4)
“See kernel/sysproc.c for the xv6 kernel code that implements the sleep system call (look for sys_sleep), user/user.h for the C definition of sleep callable from a user program, and user/usys.S for the assembler code that jumps from user code into the kernel for sleep.”
sysproc.c中定义了xv6所有用来进行 进程管理 的系统调用,比如sys_fork就在其中,而上面提到的sys_open就不在其中(而在sysfile.c中);
let’s have a look at the implementation of sys_sleep:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
uint64
sys_sleep(void)
{
int n;
uint ticks0; //记录开始休眠时的时钟周期计数
if(argint(0, &n) < 0) //令变量n存储参数寄存器a0的值
return -1;
acquire(&tickslock);
//ticks是一个全局变量,记录当前的时钟周期计数,需要加锁保护以防止并发访问导致的竞态条件
ticks0 = ticks;
while(ticks - ticks0 < n){ //时间间隔<n的时间内
//检查当前进程是否被标记为要被杀死。如果是,则释放锁并提前返回 -1
if(myproc()->killed){
release(&tickslock);
return -1;
}
sleep(&ticks, &tickslock);
}
release(&tickslock);
return 0;
}
发现函数体的第三行调用了一个
argint(0,&n),作用应该是传入一个参数0,然后得到一个返回值,存到n当中(因为&n这个参数表示的是变量n的地址,于是有这种直觉)- 查找
argint函数的定义:1 2 3 4 5 6
int argint(int n, int *ip) { *ip = argraw(n); return 0; }
果然是把一个值
argraw(n)存入了n这个变量的地址上,效果相当于n=argw(n) - 再来看
argraw(n)的定义:1 2 3 4 5 6 7 8 9 10 11 12 13 14
static uint64 argraw(int n) { struct proc *p = myproc(); switch (n) { case 0: return p->trapframe->a0; case 1: return p->trapframe->a1; ...//省略 } panic("argraw"); return -1; }
其中p->trapframe是用户进程陷入内核态时,用来保存当前用户进程运行信息的结构体(用于在系统调用完成后恢复原进程),它的内容是一堆保存了进程运行信息的寄存器(这些寄存器相当于用户进程和系统调用的桥梁):
- 通用寄存器:
ra: 返回地址寄存器sp: 栈指针gp: 全局指针tp: 线程指针t0-t6: 临时寄存器s0/fp-s11: 保存寄存器(s0 也可作为帧指针 fp)a0-a7: 参数寄存器(a0-a1 也用作返回值)
- 特殊寄存器:
epc: 异常程序计数器,记录触发异常的指令地址status: 处理器状态寄存器cause: 异常原因寄存器tval: 异常值寄存器,提供异常的附加信息
- 程序计数器:
pc: 程序计数器,指向下一条要执行的指令
可以看到,argraw用到的a0~a5就是参数寄存器,根据参数n的值来选择返回哪个参数寄存器的值;在sys_sleep中我们传入的参数是0,所以得到的返回值是用户进程所传入的a0寄存器的值。
- sleep()函数
1
sleep(&ticks, &tickslock);
调用
sleep函数使当前进程进入睡眠状态,并且指定唤醒条件为ticks变量的变化。同时传入tickslock锁,sleep函数会在进程睡眠前释放这个锁,并在进程被唤醒后重新获取这个锁。 整个sleep()系统调用的流程
a. 用户程序调用
sleep(n)函数,其函数声明定义在user.h中
b. 这个调用会跳转到usys.S中的汇编代码,跳转是由usys.S的一段汇编代码实现的
c. 汇编代码设置系统调用号并执行特殊的指令(如ecall)进入内核
d. 内核根据系统调用号找到并执行sys_sleep()函数
e.sys_sleep()完成后返回到用户空间
pingpong.c
第一次的笔记
1)代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
int pid=fork();
int fd1[2];//用于从父进程->子进程的pipe
pipe(fd1);
int fd2[2];//用于从子进程->父进程的pipe
pipe(fd2);
char buf[1]={'a'};
//child:
if(pid==0){
close(fd1[1]);
close(fd2[0]);
read(fd1[0],buf,1);
write(fd2[1],buf,1);
printf("%d: received ping\n", getpid());
exit(0);
}else{ //parent:
close(fd1[0]);
close(fd2[1]);
write(fd1[1],buf,1);
read(fd2[0],buf,1);
wait(0);
printf("%d: received pong\n", getpid());
exit(0);
}
- 要记得pid=0的是子进程
- “0读1写”
- 缓冲区buf的数据类型是
char数组- 在父/子进程中先
close掉不需要的读/写端,以防紊乱- 父进程和子进程都别忘了exit(0);
- 注意
read(fd\[0],buf,n): 第一个参数绝对不可能是fd[1],而应总是fd[0]!- 而
write(fd\[1],buf,n)的第一个参数绝对是fd[1]而不可能是fd[0],这就是“0读1写”- 读写方向(很易混淆!):
read是从管道的读端fd[0]文件读取n个字节,并写入到buf数组中;write是把buf数组中的n个字节写到管道的写端fd[1]文件中
2)等待子进程
第一次试运行pingpong程序的时候,我发现输出混乱如下:
1
56:: rreecceeiivveedd p ipnogn g
这是因为父进程和子进程的运行混到一起了,原因是忘了在父进程中用
wait(0)等待子进程;
第二次的笔记
1)记住fork()给子进程返回的是0,父进程是>0,fork失败是<0.
2)sys_pipe实现(错误处理代码一概省略了)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
uint64
sys_pipe(void)
{
uint64 fdarray; // user pointer to array of two integers
struct file *rf, *wf;
int fd0, fd1;
struct proc *p = myproc();
//将我们定义的文件描述符数组int fd[2]与上面由内核定义的地址fdarray绑定起来
//用于把内核确定的文件描述符的值传递给fd数组
if(argaddr(0, &fdarray) < 0)
return -1;
//创建、分配内存、初始化pi、rf、wf这3个结构体
if(pipealloc(&rf, &wf) < 0)
return -1;
fd0 = -1;
if((fd0 = fdalloc(rf)) < 0 || (fd1 = fdalloc(wf)) < 0){
...
}
//把内核确定的文件描述符的值传递给fd数组
if(copyout(p->pagetable, fdarray, (char*)&fd0, sizeof(fd0)) < 0 ||
copyout(p->pagetable, fdarray+sizeof(fd0), (char *)&fd1, sizeof(fd1)) < 0){
...
}
return 0;
}
我们就这个系统调用的实现代码来分别解释一下其中主要的几个函数:
1. argaddr(0, &fdarray);
这个函数和sys_sleep中的argint一样,都是从用户进程的trapframe读取寄存器的值,
存储到&fdarray这个数组地址中,参数0表示从a0参数寄存器读取。
2. pipealloc(&rf, &wf)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
int
pipealloc(struct file *f0, struct file *f1)
{
struct pipe *pi; //pi是一个pipe结构体(defined in pipe.c)
pi = 0; //初始化
*f0 = *f1 = 0;
// 为f0和f1分别分配一个file结构体的内存
if((*f0 = filealloc()) == 0 || (*f1 = filealloc()) == 0)
goto bad;
// 为pi分配一个pipe结构体的内存
if((pi = (struct pipe*)kalloc()) == 0)
goto bad;
// 设置一下pipe结构体的各个参数(pipe结构体的定义在后面)
pi->readopen = 1; //读文件打开
pi->writeopen = 1; //写文件打开
pi->nwrite = 0; //写入的bytes数
pi->nread = 0; //读取的bytes数
initlock(&pi->lock, "pipe");
//读端文件f0的属性设置 (file结构体的定义代码就不粘贴了,下面4行改动的都是file结构体的属性)
(*f0)->type = FD_PIPE;
(*f0)->readable = 1; //f0 is readable(read port)
(*f0)->writable = 0; //f0 is umwritable
(*f0)->pipe = pi;
//写端文件f0的属性设置
(*f1)->type = FD_PIPE; //f1 is writable but unreadable(write port)
(*f1)->readable = 0;
(*f1)->writable = 1;
(*f1)->pipe = pi;
return 0;
... //下面的bad错误处理程序省略了
- 详细的解释见注释
- 总之,
pipealloc()函数的作用就是为创建并初始化一个pipe结构体pi,再为作为参数传入的两个file结构体f0和f1初始化,并为这3个结构体设置相应的读/写属性。
3. struct pipe
1
2
3
4
5
6
7
8
struct pipe {
struct spinlock lock;
char data[PIPESIZE];
uint nread; // number of bytes read
uint nwrite; // number of bytes written
int readopen; // read fd is still open
int writeopen; // write fd is still open
};
4. fd0 = fdalloc(rf))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// Allocate a file descriptor for the given file.
// Takes over file reference from caller on success.
static int
fdalloc(struct file *f)
{
int fd;
struct proc *p = myproc();
//循环遍历进程的文件描述符表 (p->ofile),从0开始到 NOFILE (文件描述符的最大数量)
for(fd = 0; fd < NOFILE; fd++){
if(p->ofile[fd] == 0){
p->ofile[fd] = f;
return fd;
}
}
return -1;
}
- 要知道
ofile和NOFILE是什么 fdalloc()的大致功能:在这个循环中,查找第一个未使用的文件描述符槽位(值为0的槽位)- 当找到一个空闲槽位时:
- 将文件指针 f 存储在该槽位
- 返回该槽位的索引作为新的文件描述符
- 如果所有文件描述符都已使用,则返回 -1 表示失败
- 当找到一个空闲槽位时:
5. copyout(p->pagetable, fdarray, (char*)&fd0, sizeof(fd0))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// Copy from kernel to user.
// Copy len bytes from src to virtual address dstva in a given page table.
// Return 0 on success, -1 on error.
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
while(len > 0){
va0 = PGROUNDDOWN(dstva);
pa0 = walkaddr(pagetable, va0);
if(pa0 == 0)
return -1;
n = PGSIZE - (dstva - va0);
if(n > len)
n = len;
memmove((void *)(pa0 + (dstva - va0)), src, n);
len -= n;
src += n;
dstva = va0 + PGSIZE;
}
return 0;
}
- 这个
copyout函数实现的功能是:把内核空间的大小为len的变量src的值复制到用户空间的变量dstva上(具体实现代码等到做完lab3再回头看一下) - 在
sys_pipe中,调用这个函数达到了“把内核空间所定义的fd0和fd1这两个文件描述符的值,复制传递给了用户进程中的fdarray这个数组(fdarray是我们所定义的int fd[2]这个数组在用户地址空间中的内存地址)”的功能
6. sys_pipe总结
现在,我们可以总结sys_pipe这个系统调用的过程:
- 我在用户进程中定义一个int fd[2],但没有初始化它的元素是什么,因为文件描述符不是我可以指定的值,而是内核决定的(通过遍历当前进程的ofile来找到可分配的文件描述符)。
- 然后在sys_pipe中,把内核所确定的两个文件描述符fd0、fd1从内核空间复制到用户空间的fdarray数组中
- 那么我定义的
int fd\[2]和用户空间的fdarray是怎么“等价到一起的”?- 其实,后者就是前者在用户地址空间中的内存地址,通过
argaddr(0, &fdarray)绑定(fd就是我们的用户进程向内核空间传入的参数,存放在a0寄存器中)
- 其实,后者就是前者在用户地址空间中的内存地址,通过
3)pipe()系统调用的函数原型
1
int pipe(int* fd[2]); //fd是一个包含两个int整数的数组
参数:
- fd[0] 是管道的读取端(读端)文件描述符
- fd[1] 是管道的写入端(写端)文件描述符
返回值:
- 当 pipe() 调用成功时,它返回 0。
- 如果调用失败,则返回 -1,并设置相应的 errno 值表明失败原因。
4)整个pipe系统调用的流程
当用户调用pipe系统调用时,整个流程如下:
用户空间部分
- 用户程序定义一个整型数组:
int fd[2]; - 用户程序调用:
pipe(fd); pipe()函数通过系统调用接口陷入内核
内核空间部分
系统调用处理程序将控制权转交给
sys_pipe()函数sys_pipe()函数执行以下步骤:- 从用户栈获取
fd数组的地址,保存为fdarray - 为管道分配一个
struct pipe数据结构 - 为管道的读端和写端创建两个
struct file结构(rf和wf) - 遍历当前进程的文件描述符表
p->ofile[],找到两个空闲的文件描述符编号fd0和fd1 - 将
rf和wf分别分配给这两个文件描述符:1 2
p->ofile[fd0] = rf; p->ofile[fd1] = wf;
- 使用
copyout()函数将这两个文件描述符值复制到用户空间:1 2
copyout(p->pagetable, fdarray, (char*)&fd0, sizeof(fd0)); copyout(p->pagetable, fdarray+sizeof(int), (char*)&fd1, sizeof(fd1));
- 如果中间任何步骤失败,进行错误处理:关闭已打开的文件,清除已分配的文件描述符,返回错误码
- 从用户栈获取
sys_pipe()函数成功完成,返回到系统调用处理程序- 系统调用处理程序将控制权返回给用户程序
用户空间继续执行
pipe()函数返回,此时fd[0]包含了管道读端的文件描述符,fd[1]包含了管道写端的文件描述符- 用户程序可以使用这两个文件描述符进行读写操作:
- 对
fd[0]执行read()操作可以从管道读取数据 - 对
fd[1]执行write()操作可以向管道写入数据
- 对
primes.c
1)注意
- 在write语句的下一行必须紧接着close写端
1 2 3
write(p[1],buf,34); close(p[1]);//close写端应该紧跟在write后面! wait(0);
- read之后,要怎么存储read到的数据?
1 2
int prime; read(p[0], &prime, 4);
其中:
&prime是目标缓冲区的地址。这里prime是一个整型变量,前面加&表示取这个变量的内存地址。read()函数会将读取的数据存储到这个地址指向的内存空间中。- 一个
int类型占用 4 个字节,这里 ==4代表只读取一个整数== 的字节数。
后面:
1
2
3
if(read(p[0], &n, 4)){
...;//如果后续还有数字...
}
我们发现这里的缓冲区使用了一个新的int变量n而不是原来的prime,这是因为后面我们要用prime来循环处理剩余的数字,过滤掉能被prime整除的数字。
怎么做到“递归创建管道和子进程”?
方法是用一个new_proc函数,当if(pid==0)时调用它,在它内部if(read(p[0], &n, 4))(也就是当还有数字可读)时递归调用它自身。- 怎么检测管道中还有可以读取的字节?
1
if(read(p[0], &n, 4)>0)...//如果读取到的字节数>0
- 注意read/write的字节数是多少
1
write(p[1], buf, 34 * sizeof(int));
一开始这里我写的是34,但是这个参数的含义是“字节数”,所以还要乘以
sizeof(int)。
2)实现
这里贴上这篇blog的实现,因为我自己的实现不是很优雅(比如read
/write和尾部判断的方法比较笨拙)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
// 一次 sieve 调用是一个筛子阶段,会从 pleft 获取并输出一个素数 p,筛除 p 的所有倍数
// 同时创建下一 stage 的进程以及相应输入管道 pright,然后将剩下的数传到下一 stage 处理
void sieve(int pleft[2]) { // pleft 是来自该 stage 左端进程的输入管道
int p;
read(pleft[0], &p, sizeof(p)); // 读第一个数,必然是素数
if(p == -1) { // 如果是哨兵 -1,则代表所有数字处理完毕,退出程序
exit(0);
}
printf("prime %d\n", p);
int pright[2];
pipe(pright); // 创建用于输出到下一 stage 的进程的输出管道 pright
if(fork() == 0) {
// 子进程 (下一个 stage)
close(pright[1]); // 子进程只需要对输入管道 pright 进行读,而不需要写,所以关掉子进程的输入管道写文件描述符,降低进程打开的文件描述符数量
close(pleft[0]); // 这里的 pleft 是*父进程*的输入管道,子进程用不到,关掉
sieve(pright); // 子进程以父进程的输出管道作为输入,开始进行下一个 stage 的处理。
} else {
// 父进程 (当前 stage)
close(pright[0]); // 同上,父进程只需要对子进程的输入管道进行写而不需要读,所以关掉父进程的读文件描述符
int buf;
while(read(pleft[0], &buf, sizeof(buf)) && buf != -1) { // 从左端的进程读入数字
if(buf % p != 0) { // 筛掉能被该进程筛掉的数字
write(pright[1], &buf, sizeof(buf)); // 将剩余的数字写到右端进程
}
}
buf = -1;
write(pright[1], &buf, sizeof(buf)); // 补写最后的 -1,标示输入完成。
wait(0); // 等待该进程的子进程完成,也就是下一 stage
exit(0);
}
}
int main(int argc, char **argv) {
// 主进程
int input_pipe[2];
pipe(input_pipe); // 准备好输入管道,输入 2 到 35 之间的所有整数。
if(fork() == 0) {
// 第一个 stage 的子进程
close(input_pipe[1]); // 子进程只需要读输入管道,而不需要写,关掉子进程的管道写文件描述符
sieve(input_pipe);
exit(0);
} else {
// 主进程
close(input_pipe[0]); // 同上
int i;
for(i=2;i<=35;i++){ // 生成 [2, 35],输入管道链最左端
write(input_pipe[1], &i, sizeof(i));
}
i = -1;
write(input_pipe[1], &i, sizeof(i)); // 末尾输入 -1,用于标识输入完成
}
wait(0); // 等待第一个 stage 完成。注意:这里无法等待子进程的子进程,只能等待直接子进程,无法等待间接子进程。在 sieve() 中会为每个 stage 再各自执行 wait(0),形成等待链。
exit(0);
}
【这一道主要的坑】
stage 之间的管道 pleft 和 pright,要注意关闭不需要用到的文件描述符,否则跑到 n = 13 的时候就会爆掉,出现读到全是 0 的情况。
理由是,fork 会将父进程的所有文件描述符都复制到子进程里,而 xv6 每个进程能打开的文件描述符总数只有 16 个 (见 defs.h 中的 NOFILE 和 proc.h 中的 struct file *ofile[NOFILE]; // Open files)。
由于一个管道会同时打开一个输入文件和一个输出文件,所以一个管道就占用了 2 个文件描述符,并且复制的子进程还会复制父进程的描述符,于是跑到第六七层后,就会由于最末端的子进程出现 16 个文件描述符都被占满的情况,导致新管道创建失败。
【解决方法】
关闭管道的两个方向中不需要用到的方向的文件描述符(在具体进程中将管道变成只读/只写)
find.c
1)ls.c中,读取目录directory信息的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
void read_directory(char *path) {
int fd;
struct dirent de;//用于存储目录条目(directory entries)的结构体
struct stat st;//用于存储目录信息(status)的结构体
char buf[512], *p;//缓冲区
// 打开目录
if((fd = open(path, 0)) < 0){
fprintf(2, "cannot open %s\n", path);//打开失败则输出报错
return;
}
// 获取目录状态
if(fstat(fd, &st) < 0){//从目录(用文件描述符fd表示)中读取目录的状态,存储到st结构体中
fprintf(2, "cannot stat %s\n", path);//获取失败则报错
close(fd);
return;
}
// 确认是目录类型
if(st.type != T_DIR) {
fprintf(2, "%s is not a directory\n", path);//不是目录类型则报错
close(fd);
return;
}
// 准备路径缓冲区p
strcpy(buf, path);
p = buf + strlen(buf);//将指针 `p` 定位到字符串 `buf` 的末尾
*p++ = '/';
// 读取目录中的所有条目
while(read(fd, &de, sizeof(de)) == sizeof(de)){
// 跳过无效条目
if(de.inum == 0)//inum等于0表示该条目没有被使用,也就是没记录任何文件的信息
continue;
// 构建完整路径
memmove(p, de.name, DIRSIZ);//将目录条目de中的文件名`de.name`复制到缓冲区`p`,长度为`DIRSIZ`。
p[DIRSIZ] = 0; // 添加字符串结束符
// 处理当前条目
if(stat(buf, &st) < 0){
printf("cannot stat %s\n", buf);
continue;
}
printf("%s\n", buf);
}
// 关闭目录
close(fd);
}
路径缓冲区
buf的作用:组装文件的路径和文件名,比如在/home/user路径下发现了文件document.txt,则借助buf构建出/home/user/document.txt这个完整路径inode:用于存储文件元数据的数据结构,包含:文件类型(普通文件、目录、链接等)、文件大小、时间戳(创建时间、修改时间等)、指向实际数据块的指针等dirent和stat:定义在头文件和<sys/stat.h>中 inum:目录条目(de)中的信息之一,表示”inode number”,是标识文件的唯一数字ID
inode号为0通常表示未使用的目录条目
多个目录条目可以指向同一个inode号(硬链接)T_DIR, T_FILE: 在 xv6 中,这些文件类型常量是在内核代码中预先定义的,通常在文件系统相关的头文件中(如 fs.h)。内核在创建文件或目录时会设置它们的类型。
2)find.c相比于ls.c修改的地方
第1处:跳过目录条目的条件
1
2
3
//if的条件增加了后面这两个
if(de.inum == 0 || strcmp(de.name, ".") == 0 || strcmp(de.name, "..") == 0)
continue;//跳过满足if条件的表项
strcmp(de.name, ".") == 0- 检查目录项的名称是否为”.”。在Unix/Linux文件系统中,”.”表示当前目录。在递归搜索时,我们通常想跳过当前目录以避免无限循环。strcmp(de.name, "..") == 0- 检查目录项的名称是否为”..”。在Unix/Linux文件系统中,”..”表示父目录。同样,在递归搜索时跳过父目录可以避免循环和重复搜索。
1
2
3
4
5
6
7
8
9
10
假设我们有一个名为documents的目录,其中有两个文件report.txt和notes.pdf,以及一个子目录projects。
如果我们用ls -la documents命令查看该目录,可能会看到类似这样的输出:
Copydrwxr-xr-x 4 user group 128 Mar 10 15:30 .
drwxr-xr-x 18 user group 576 Mar 09 10:15 ..
-rw-r--r-- 1 user group 2048 Mar 10 14:20 report.txt
-rw-r--r-- 1 user group 4096 Mar 08 09:45 notes.pdf
drwxr-xr-x 3 user group 128 Mar 07 16:30 projects
其中"."和".."分别是当前目录和父目录
第2处:便利目录条目时,对每一个目录条目的处理
1
2
3
4
5
6
7
if(st.type==T_DIR){//如果当前的条目也是一个目录,那对这个字目录也find一下有没有目标文件
find_helper(buf,target);
}else if(st.type==T_FILE){//如果当前的条目是一个数据文件,就比较一下文件名是不是目标文件
if(strcmp(de.name,target)==0){
printf("%s\n",buf);
}
}
3)目录文件和数据文件
在文件系统中,目录(directory)和数据文件(.txt等)本质上都是以文件描述符来表示的。
在现代操作系统中,目录实际上是一种特殊类型的文件,它包含了指向其他文件或目录的引用信息。系统通过这些文件描述符来管理和组织文件系统层次结构。
主要区别在于:
- 目录文件存储的是其包含的文件和子目录的名称以及对应的索引节点(inode)信息
- 普通数据文件(如.txt文件)存储的是实际的内容数据
操作系统通过不同的权限和属性来区分它们,但在底层实现上,它们都是通过文件描述符进行管理的,都可以被打开、读取和关闭,只是处理方式不同,所以find.c中可以用int fd = open(path, 0))来获取输入的这个路径path(如/a/b)的文件描述符。
4)dirent, stat结构体
dirent 结构体
dirent(directory entry)结构体用于表示目录中的条目,由readdir()函数获取,它提供了目录中文件的基本信息:
1
2
3
4
5
6
7
struct dirent {
ino_t d_ino; // 文件的inode号
off_t d_off; // 在目录文件中的偏移量
unsigned short d_reclen; // 此记录的长度
unsigned char d_type; // 文件类型 (并非所有文件系统都支持)
char d_name[]; // 文件名
};
stat 结构体
stat结构体则包含了文件的详细元数据信息,通常通过stat()、fstat()或lstat()函数获取:
1
2
3
4
5
6
struct stat {
dev_t st_dev; // 设备ID
ino_t st_ino; // inode号
nlink_t st_nlink; // 硬链接数
...
};
区别:
dirent主要用于目录遍历,获取目录内容列表(但记住每一个dirent只是目录中的一个条目),如1 2 3 4 5
// 读取目录中的所有条目 while(read(fd, &de, sizeof(de)) == sizeof(de)){ if(de.inum == 0){continue;}//记得跳过无效条目 ... }
stat用于获取单个文件的详细元数据(但也可用于获取目录的信息,因为目录本质上也是一种特殊类型的文件,如上文中的1
if(fstat(fd, &st) < 0))
联系:
在实际编程中,这两个结构体经常一起使用 - 先用dirent遍历目录获取文件名,然后对感兴趣的文件使用stat获取详细信息。
xargs.c
这个程序实现了一个简化版的 UNIX xargs 工具。
readline 函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
int readline(char *new_argv[32], int curr_argc) {
static char buf[1024];
int n = 0;
// 从标准输入逐字符读取一行
while(read(0, buf+n, 1)) {
if (buf[n] == '\n') {//遇到换行符,即已至行尾,停止读取
break;
}
n++;
}
buf[n] = 0; // 将读取的字符串以null终止
if (n == 0) return 0; // 如果没有读取到任何字符,返回0
int offset = 0;
// 解析读取的行,按空格分割为参数
while(offset < n) {
// 将当前参数指针存入new_argv数组
new_argv[curr_argc++] = buf + offset;
// 跳过非空格字符
while(buf[offset] != ' ' && offset < n) {
offset++;
}
// 将空格替换为null字符,并跳过连续空格
while(buf[offset] == ' ' && offset < n) {
buf[offset++] = 0;
}
}
return curr_argc; // 返回参数总数
}
- 这个函数从标准输入读取一行文本,然后将其分割为多个参数(以空格为分隔符),并将这些参数添加到
new_argv数组中。 - 使用
static char buf[1024]的==static==意味着缓冲区在函数调用之间保持不变,这允许后续解析不会覆盖之前的数据。
==后半部分的三个嵌套的while(一个大while里有两个小while)==:
假设buf中包含字符串 “hello world example”(n = 19):
- 第一次循环开始:offset = 0
- new_argv[curr_argc++] = buf + 0; (指向”hello world example”的开头)
- 内部循环1:offset前进到5(跳过”hello”)
- 内部循环2:将位置5的空格替换为’\0’,offset变为6
- 第二次循环开始:offset = 6
- new_argv[curr_argc++] = buf + 6; (指向”world example”的开头)
- 内部循环1:offset前进到11(跳过”world”)
- 内部循环2:将位置11的空格替换为’\0’,offset变为12
- 第三次循环开始:offset = 12
- new_argv[curr_argc++] = buf + 12; (指向”example”的开头)
- 内部循环1:offset前进到19(跳过”example”)
- 内部循环2:不执行(没有更多空格)
循环结束,new_argv数组现在包含三个参数的指针,分别指向buf中的”hello”、”world”和”example”三个null终止的字符串。
值得关注的是
buf+n这种数组名+偏移量的形式,因为write/read的第二个参数(缓冲区)必须是一个地址(只传入一个buf作为第二个参数也是作为地址传入,第三个参数指定了往这个地址写入/读取多少个字节)
main 函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
int main(int argc, char const *argv[]) {
if (argc <= 1) {//如果输入的命令行参数太少
fprintf(2, "Usage: xargs command (arg ...)\n");
exit(1);
}
// 为命令名分配内存并复制,目的是创建命令名的一个独立副本,这样程序就可以在不修改原始 `argv` 数组的情况下操作命令名。
char *command = malloc(strlen(argv[1]) + 1);//malloc为存储命令名称分配内存,并将返回的指针赋值给 `command` 变量,+1是为了多分配一个空间来存储结束符\0
strcpy(command, argv[1]);//将命令名从 `argv[1]` 复制到新分配的内存中
char *new_argv[MAXARG];
// 复制原始命令行参数(之所以不和前面那两行分开写,是因为argv[1]是命令名,如echo;而后面的argv[i]是命令行参数,如-n)
for (int i = 1; i < argc; ++i) {
new_argv[i - 1] = malloc(strlen(argv[i]) + 1);
strcpy(new_argv[i - 1], argv[i]);
}
int curr_argc;
// 持续读取标准输入的每一行
/*readline函数返回该行读取到的命令行参数的个数,如果为0,
则表示没有读取到任何参数(可能是到达了文件末尾EOF),循环结束*/
while((curr_argc = readline(new_argv, argc - 1)) != 0) {
new_argv[curr_argc] = 0; // 参数数组以NULL结尾
// 创建子进程执行命令
if(fork() == 0) {
exec(command, new_argv);//command是之前创建的命令名的副本、new_argv是之前创建的命令行参数的副本
fprintf(2, "exec failed\n");//这两行代码只有在 `exec` 调用失败时才会执行
//因为在正常情况下,`exec`会替代当前进程,exec成功后代码就不会继续执行
exit(1);
}
wait(0); // 等待子进程完成
}
exit(0);
}